Mögliche Komponenten eines Archäologischen Informationssystems
Gemäß unserer Definition besteht ein Archäologisches Informationssystem aus den Komponenten Menschen, Daten, Informationen, Hardware und Software. In Abbildung I.5 sind diese Komponenten dargestellt.
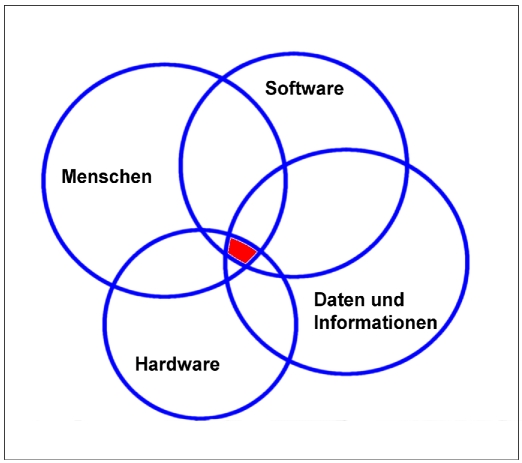
Abb. I.5 Mögliche Komponenten eines Archäologischen Informationssystems. Es besteht aus Menschen, Daten, Informationen, Hardware und Software.
Im Folgenden wollen wir näher auf die einzelnen Komponenten eingehen.
Menschen
Ein Informationssystem hat nur eine Berechtigung, falls es dem Menschen nützt ( vgl. die Definition eines Informationssystems in ALBRECHT 1973, S. 3). Es sollte also Archäologinnen bei der täglichen Arbeit sinnvoll unterstützen. Ihretwegen werden Archäologische Informationssysteme geschaffen. Sie sind die Zielgruppe und formulieren ihre Anforderungen an das zu entwickelnde Informationssystem. Nach ihren Vorgaben entwickeln Programmierer und Softwareingenieure entsprechende Informationssysteme. Wie das geht, ist im Kapitel Entwurf eines Archäologischen Informationssystems angedeutet. Archäologinnen sind also der Ursprung und Ausgangspunkt von Archäologischen Informationssystemen und damit ihre wichtigste Komponente. Dies wird oft nicht bedacht und die "technische" Kompetenz wird im Vordergrund gesehen. Sie ist jedoch nachrangig - ohne die Archäologin, die ein entsprechendes Informationssystem nutzt hat ein System keine Existenzberechtigung.
Außer den späteren (Haupt-)nutzerinnen, den Archäologinnen sind viele andere Menschen an der Konzeption, Entwicklung und Anwendung von Archäologischen Informationssystem beteiligt. Beispielsweise Programmierer, Geographen, Geodätinnen, Bauforscher, Geo-Medieninformatiker usw.
Informationen und Daten
Was ist der Unterschied zwischen Daten und Informationen? Wie werden aus Informationen Daten und wie werden aus Daten Informationen?
Antworten auf diese Fragen gibt Langefors 1976 in seinem Aufsatz mit dem Titel "Information, in the Context of the Information System" (vgl. LANGEFORS 1976, S. 24 "Information, Data and Reality" und LANGEFORS 1970, S. 231, Kap. 23.4 "The meaning of Information within a system"). In der neueren Literatur hat sich gegenüber den Erklärungen von Langefors nicht sehr viel verändert.
Ein einfaches Beispiel für ein "Datum" wäre die Zahl 33. Diese Zahl wird vom "Datum" zur Information, falls wir den Kontext wissen. Unter Kontext verstehen wir eine Beschreibung, was diese Zahl bedeuten soll. Diese Beschreibung wird oft mit dem Begriff Metadaten bezeichnet. Wissen wir beispielsweise, dass die Zahl 33 eine Temperaturangabe sein soll, besitzen wir die Information, dass es warm ist. Besitzen wir die zusätzliche Information, dass es sich um die Außentemperatur handelt, würden wir es wahrscheinlich als heiß bezeichnen. Ebenso könnte der Kontext das Lebensalter oder eine Fundnummer sein. Falls wir die Zahl 33 ohne jegliche Beschreibung in einer Datei gespeichert haben, handelt es sich um ein "Datum". Dieses wird erst durch den Kontext wieder zur Information. Dieser Kontext könnte bereits mit der Benennung des Eingabefeldes in einer Datenbank als "Fundnummer" oder als "Temperaturangabe" gegeben sein.
Gray et al. (1992) beschreiben den Unterschied zwischen Information und Daten in sehr kurzer Form: Wenn Information gespeichert und verarbeitet werden soll, ist diese in einer beschreibenden Form zu speichern. Diese Informationen nennt man Daten (GREY et al. 1992, S. 2).
Datentypen und Datenformate
Wie werden nun die Daten im Computer gespeichert? In der Regel werden Daten mit einem Programm, das auf einer bestimmten Hardware abläuft erfasst und in einem bestimmten Datenformat gespeichert. Die gespeicherten Daten lassen sich dann verarbeiten und gegebenenfalls wieder ausgegeben. Die kleinste Einheit für die Speicherung von Daten ist das Bit (engl. Abk. für Binary digit). Ein Bit gibt im einfachsten Fall einen Zustand wieder, beispielsweise Strom ein oder Strom aus. Dabei wird jedem dieser beiden Zustände ein Wert zugeordnet, hier beispielsweise 0 für den Zustand Strom ein und 1 für den Zustand Strom aus. Die Informationseinheit Bit kann also genau zwei Zustände abbilden. Stehen zwei Bits zur Verfügung, lassen sich bereits 22, also 4 Zustände abbilden.
Aus einzelnen Bits setzen sich Bytes zusammen. Jedes Byte ist eine Abfolge von acht Bits. Eine Datei wird im Computer als Abfolge von Bytes oder Bits gespeichert. Die Größen von Dateien und Speichern werden in Bytes angegeben. Die Abkürzung dafür ist B. Wir werden später Rasterdateien kennenlernen, in denen Graphiken als Abfolgen von Bits gespeichert werden, weshalb sie auch Bitmaps heißen. Gängige Größenbezeichnungen von Dateien und Speichern sind in Abbildung I.6 zu sehen.
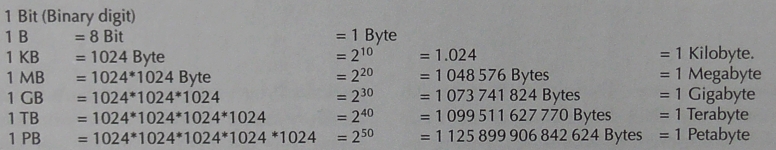
Abb. I.6 Bits und Bytes. Gängige Größenbezeichnungen für Speicher und Dateien.
Der Abbildung I.6 lässt sich entnehmen, dass 1 Kilobyte (1 KB) etwas mehr als 1000 Bytes ergibt, nämlich 1024 Bytes. Da sich diese Zahl nur geringfügig von 1000 unterscheidet, wurde die Bezeichnung Kilo in Anlehnung an andere Maßeinheiten gewählt. Gleiches gilt für MEGA, Giga, Tera und Petabyte.
Daten sind in Dateien in festen Formaten abgespeichert. Das bedeutet, dass es sich nicht um eine einfache Aneinanderreihung von Bits oder Bytes handelt, sondern dass die Daten weiter strukturiert sind. Zahlen werden in bestimmten Datentypen gespeichert, Buchstaben ebenso. In Abbildung I.7 sind einige Datentypen aus der Programmiersprache C++ aufgelistet.

Abb. I.7 Eine Auswahl von Datentypen aus der Programmiersprache C++.
Für die Speicherung von Zahlen gibt es in C++ unterschiedliche Datentypen. Die Größe der Datentypen (in Bytes) variiert je nach der gewünschten Genauigkeit. So läßt sich eine ganze Zahl zwischen -128 und +127 mit einem Byte im Datentyp "__int8" abspeichern. Größere Zahlen mit Nachkommastellen benötigen andere Datentypen mit mehr Speicherplatz, beispielsweise den Datentyp "double" mit einer Größe von 8 Bytes.
Um mit einem Programm auf eine Datei zugreifen zu können, benötigt der Programmierer eines entsprechenden Programms die Datenstruktur mit den Datentypen der Datei. Meist existiert hierfür eine Beschreibung oder das Datenformat (= die Datenstruktur) ist genormt. Ebenso spielen die Datentypen bei der Konvertierung von Daten eine wichtige Rolle. Werden die Datentypen der zu zu konvertierenden Dateien nicht beachtet, können wichtige Informationen verloren gehen. Wird beispielsweise ein Programm benutzt, das Daten aus einer Totalstation mit einer Genauigkeit von 6 Nachkommastellen in ein anderes Format umwandeln soll, dann ist darauf zu achten, dass Ausgangs- und Zieldatei den gleichen Datentyp besitzen. Besitzt die Ausgangsdatei beispielsweise den Datentyp "double" für die Speicherung der Koordinaten aus der Totalstation und die Zieldatei den Datentyp "__int16", würden lediglich Koordinaten im Wertebereich von -32768 bis +3276 gespeichert. Die Nachkommastellen würden abgeschnitten werden. Würde die Zieldatei aus einem größeren Datentypen, etwa "long double" bestehen, würden die Daten ordnungsgemäß konvertiert werden.
Wir kommen jetzt zu den Datenformaten. Alle Datenformate sind aus bestimmten Datentypen aufgebaut. In Abbildung I.8 haben wir Datenformate aufgelistet, die im Augenblick häufig in Archäologischen Informationssystemen benutzt werden.
Bei Datenformaten sind die in Abbildung I.8 genannten Dateiendungen bezüglich der beschriebenen Bedeutung und Verwendung allgemein üblich, jedoch nicht zwingend notwendig. Es kann also durchaus vorkommen, dass in einer Datei mit dem Namen Programm.txt der Quellcode eines Programmes in der Programmiersprache C enthalten ist. Ebenso könnte in einer Datei mit der Endung DBF nur Text vorhanden sein. Diese Eigenschaft von Dateinamen wird beispielsweise mißbraucht, um in "harmlos" erscheinenden Dateien Computerviren zu verstecken. Die Dateinamen sind häufig durch einen oder mehrere Punkte getrennt. Verschiedene Betriebssysteme lassen unterschiedliche Dateinamen zu. So könnte eine Textdatei zum Beispiel Text.txt heißen, ebenso wäre Text.txt.ps denkbar.

Abb. I.8 Eine Auswahl der am häufigsten in AIS verwendeten Datenformate.
In der Abbildung I.8 wird bereits eine Gliederung der Datenformate deutlich. Es existieren spezielle Datenformate für Programmiersprachen und Text, für Datenbanken, Rasterdaten, Videodaten, Vektordaten, Druckdateien und für komprimierte Dateien. Wir werden einzelne Datenformate in den weiteren Kapiteln noch näher kennenlernen. Für viele Formate existieren internationale Normen, beispielsweise für das Format SGML und das davon abgeleitete Format HTML. Andere Formate haben sich als "Standard" durchgesetzt, wie beispielsweise PDF und RTF, sind jedoch nicht genormt.
Wir wollen uns im Folgenden etwas intensiver mit Text-, Raster und Vektordaten beschäftigen.
Textdaten
Text wird in der Regel in einem genormten Zeichensatz in Dateien abgespeichert. Viele Zeichensätze unterliegen einer internationalen Normung. Die bekanntesten Normen sind der American Standard Code for Information Interchange (ASCII) und neuerdings Unicode. Unicode bietet als "16-Bit-Code" die Möglichkeit in einer Zeichensatztabelle bis zu 216 = 65536 Zeichen zu speichern (vgl. BOHN, DÜRST 1997, S. 159). Damit ist ein einheitlicher Standard (auch für Sonderzeichen) geschaffen worden. Textdaten werden meist durch Dateneingabe in einem Textverarbeitungsprogramm erzeugt. Bei der Speicherung der erfassten Textdaten stellt sich grundsätzlich die Frage, in welchem Format die Daten gespeichert werden sollen. Im ASCII-Format, im Unicode-Format oder in einem speziellen Textformat mit besonderen Schriftzeichen.
Falls wir die Daten nicht in einem international genormten Standardformat speichern, fehlen uns häufig die Programme zum schnellen Lesen der Daten. Sollten wir deshalb alle unsere Daten im ASCII oder Unicode-Format speichern? Harrison Eiteljorg II hat diese Frage im Kontext der Speicherung von archäologischen Daten bereits 1995 diskutiert (vgl. EITELJORG II 1995, S. 246).
Obwohl PostScript (ps) im Grunde eine Beschreibungssprache für die Ausgabe von Seiten an einen Drucker darstellt, soll das Format hier erwähnt werden. Diese Seitenbeschreibungssprache wurde in der 1980er Jahren von dem amerikanischen Hersteller Adobe entwickelt und wird heute sehr häufig angewandt. Es lassen sich beliebige Elemente, wie Text und Graphiken in eine Ausgabeseite einbinden. Der große Vorteil der Seitenbeschreibungssprache PostScript besteht in der Unabhängigkeit von bestimmten Ausgabegeräten. Jeder Drucker oder Plotter, der diese Sprache interpretieren kann (der "postscriptfähig" ist), kann die so beschriebenen Seiten ausgeben. Eine Sonderform dieses Formats stellt das Encapsulated PostScript-Format dar.
Als augenblicklicher Standard für digitale Publikationen, beispielsweise für die "online"-Publikation von Dissertationen, ist das "Portable Document Format" (PDF) anzusehen. Weiterhin werden digitale Publikationen mit den Beschreibungssprachen "Standard Generalized Markup Language" (SGML) und "Hyper Text Markup Language" (HTML) herausgegeben. Letztere wird insbesondere für Publikationen im Internet benutzt (vgl. auch das Anwendungsbeispiel in Teil II). Die Einbindung von Graphiken, Video- und Audiodateien ist problemlos möglich (vgl. RAHTZ, HALL, ALLEN 1992).